공유메모리란?
여러 프로세서 (CPU)들이 메모리를 공유하며, 프로세서 사이의 통신이 공유메모리를 통해 이루어지는 것을 말한다. 프로세스를 하나 실행시키면, 그 프로세스가 여러쓰레드를 포크하고, 그렇게 생성된 쓰레드들은 테스크를 병렬로 수행한다. 쓰레드사이의 통신은 프로그램 안에 있는 공유변수를 이용하여 이루어진다.
*Thread: 쓰레드는 프로세스보단 상대적으로 가벼우며, 보통 공유메모리 프로그램은 하나의 프로세스와 여러개의 쓰레드로 이루어진다. 자신을 생성시킨 프로세스와 address space를 공유하고 프로세스의 data에 접근이 가능하다. 프로세스 안의 쓰레드 끼리는 공유변수를 통해 통신이 가능하며 서로 제어도 가능하다. parent 쓰레드에 변화가 생기면 child쓰레드또한 영향을 받고, 생성/관리에는 오버헤드가 거의 없다.

Pthreads란?
POSIX Threads를 줄여서 Pthreads라고 부른다. POSIX는 Portable Operating System Interface X 의 줄인말로, UNIX계열 OS의 공통 API를 정리하여 이식성 높은 유닉스 응용프로그램을 개발하기위한 목적으로 IEEE가 책정한 API규격이다. Pthreads API는 멀티쓰레드 프로그래밍의 API이고 C언어와 링크하여 사용가능하다. 또한 POSIX인 리눅스, 맥, Solaris, HPUX에서만 사용이 가능하다.
1. Hello World! 예제
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h> //pthread 라이브러리
int thread_count; //공유변수
void *Hello(void *rank); //쓰레드 함수
int main(int argc, char *argv[]){
long thread; //쓰레드변수
pthread_t* thread_handles; //thread handle을 담을 배열
thread_count=strtol(argv[1],NULL,10); //10진수로 쓰레드 개수받기
thread_handles=malloc(thread_count *sizeof(pthread_t)); //배열생성
for(thread=0;thread<thread_count;thread++)
pthread_create(&thread_handles[thread],NULL,Hello,(void*)thread); //쓰레드생성
printf("Hello from the main thread.\n");
for(thread=0;thread<thread_count;thread++)
pthread_join(thread_handles[thread],NULL); //쓰레드 종료확인, 함수반환값받아옴
free(thread_handles);
return 0;
}
void *Hello(void *rank){
long my_rank=(long) rank;
printf("hello, from thread %ld of %d\n",my_rank,thread_count);
return NULL;
}
-전역변수는 모든 스레드가 공유하지만, 함수의 파라미터와 지역변수들은 그 함수를 실행하는 스레드한테만 private하다. 전역변수는 꼭 필요시에만 사용된다.
-스레드를 생성할때는 꼭 정해진 문법에 의해서만 생성해야하고, 스레드의 종료를 확인해야한다. 함수호출시에 스레드가 실행을 끝내지 않았다면 종료될때까지 기다리기 때문에 pthread_join()을 실행하여 종료확인을 해주어야한다.
2. matrix-vector multiplication 예제
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define m 100
#define n 100
int thread_count; //공유변수
int A[m][n], y[m],x[n]; //전역배열
void *Pth_mat_vect (void *rank){
long my_rank=(long) rank; //스레드 번호
int i,j;
int local_m=m/thread_count; //스레드 1개가 처리할 행의 수
int my_first_row =my_rank * local_m;
int my_last_row=(my_rank+1) *local_m-1;
for(i=my_first_row;i<=my_last_row;i++){
y[i]=0.0;
for(j=0;j<n;j++)
y[i]+=A[i][j]*x[j];
}
return NULL;
}
int main(int argc, char *argv[]){
long thread;
pthread_t* thread_handles;
int i,j;
for(i=0;i<n;i++)
x[i]=2; //2로 초기화
for(i=0;i<m;i++)
for(j=0;j<n;j++)
A[i][j]=3; //3으로초기화
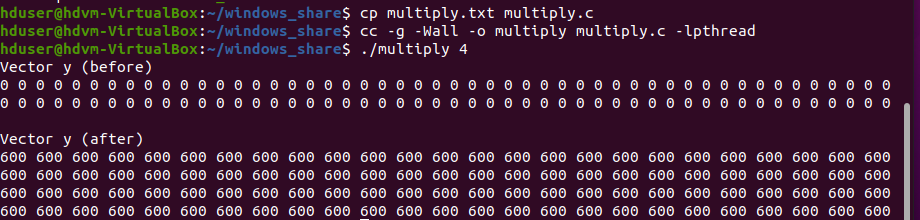
printf("Vector y (before)\n"); // 곱하기전 벡터 출력
for(i=0;i<m;i++)
printf("%d ",y[i]);
printf("\n\n");
thread_count=strtol(argv[1],NULL,10); //스레드개수
thread_handles =malloc(thread_count* sizeof(pthread_t)); //스레드배열
for(thread=0;thread<thread_count;thread++) //스레드 생성
pthread_create(&thread_handles[thread],NULL,Pth_mat_vect, (void*) thread);
for(thread=0;thread<thread_count;thread++) //스레드 종료
pthread_join(thread_handles[thread],NULL);
free(thread_handles);
printf("Vector y (after) \n");
for(i=0;i<m;i++)
printf("%d ",y[i]);
return 0;
}
3. critical sections
*critical section이란?
공유변수영역에서 둘 이상의 스레드가 동시에 접근해서는 안되는 공유 자원을 접근하는 코드의 일부를 말한다. 공유변수를 스레드들이 같이 읽고 쓰기 때문에 race condition이 발생하여 계산의 정확도가 낮아지는 현상이 나타날 수 있다. 파이를 계산하는 것을 예로들면, 파이를 계산하는 과정에서 공유변수 sum을 스레드들이 같이 읽고 쓰게 된다. 이때 sum의 값을 가져오고, 덧셈을하고, 계산결과를 sum에 저장하는 이 3단계 과정이 스레드 제각각 이루어지기 때문에 계산 결과가 맞지 않는 현상이 일어난다.
해결방법 1) Busy waiting을 사용한 공유 변수 접근
flag는 mainthread가 0으로 초기화해 놓고, 굥유변수에 접근하기 위해 스레드 my_rank는 자기 차례가 올때까지 기다리는 방법이다.
void &Thread_sum(void *rank){
long my_rank=(long) rank;
double factor, my_sum=0.0; //지역변수
long long i;
long long my_n=n/thread_count;
long long my_first_i=my_n*my_rank;
long long my_last_i=my_fiirst_i+my_n;
if(my_first_i%2==0)
factor=1.0;
else
factor=-1.0;
for(i=my_first_i;i<my_last_i;i++,factor=-factor)
my_sum+=factor/(2*i+1);
while(flag!=my_rank);
sum+=my_sum; //sum, flag는 공유변수
flag=(flag+1)%thread_count; //flag증가
return NULL;
}
해결방법 2) Mutex를 사용한 공유 변수 접근
mutex는 스레드가 변수에 접근하는데 제한을 두는 변수이다. 한 스레드가 공유변수에 접근하고 있으면 다른 스레드는 그 변수에 접근할 수 없다. mutex는 pthread_mutex_t로 선언된다. 일반적으로 busy-wait보단 mutex가 더 빠르다.
pthread_mutex_t mutex =PTHREAD_MUTEX_INITIALIZER; //mutex초기화, mutex변수는 전역변수
void *Thread_sum(void *rank){
long my_rank=(long) rank;
double factor;
long long i;
long long my_n=n/thread_count;
long long my_first_i=my_n*my_rank;
long long my_last_i=my_first_i+my_n;
double my_sum=0.0;
if(my_first_i%2==0)
factor=1.0;
else
factor=-1.0;
for(i=my_first_i;i<my_last_i;i=+,factor-factor)
my_sum+=factor/(2*i+1);
pthread_mutex_lock(&mutex); //lock
sum+=my_sum; //critical section
pthread_mutex_unlock(&mutex); //unlock
return NULL;
}
위에 나온 두 방법 모두 critical sections에서 공유변수를 여러스레드가 이용하는 것을 막는다. 하지만 mutex를 이용하는 방법은 스레드 끼리의 순서가 중요한 프로그래밍에서는 사용하지 못한다. 반면, busy-wait는 스레드순서를 정해줄 수는 있지만 효율성이 매우 떨어진다. 이 2가지의 방법외에도 Semaphore를 이용하는 방법도 있다.
해결방법 3) Semaphores를 사용한 공유 변수 접근
semaphore는 사용가능한 자원의 개수를 기억하고 있는 것이다. semaphore는 unsigned int이고, 만약 그 값으로 0과 1만 사용한다면 binary semaphore가 된다. (0: locked 1: unlocked) critical section을 보호하려면 그 앞에 sem_wait()를 두는데, 이때 만약 semaphore의 값이 0이면 대기하고, 0이 아니면 그값을 1만큼 감소시키고 진행한다. 그 후에, sem_post()를 호출해서 semaphore의 값을 다시 1만큼 증가시킨다. 이때 만약 sem_wait()에서 대기중이던 thread가 있었다면 그 thread는 진행된다.
#include <semaphore.h> //semaphore헤더파일
int sem_init{ //sem_init(&sem1,0,0) 으로 초기화해주면된다
sem_t* semaphore_p,
int shared,
unsigned initial_val);
int sem_destroy(sem_t* semaphore_p);
int sem_post(sem_t* semaphore_p);
int sem_wait(sem_t* semaphore_p);
}
//메인에서 semaphore는 0으로 초기화되어있다고 가정
void* Send_msg(void* rank){
long my_rank=(long) rank;
long dest=(my_rank+1)*thread_count;
char* my_msg=malloc(MSG_MAX*sizeof(char));
sprint(my_msg, "Hello to %ld from %ld",dest,my_rank);
message[dest]=my_msg; //send
sem_post(&semaphores[dest]); //lock
sem_wait(&semaphores[my_rank]); //access
printf("Thread %ld >%s\n",my_rank,message[my_rank]);
return NULL;
}
처음부터 lock이 걸려있는 상황이다. message를 쓴다음에 그 lock을 풀어주어 dest스레드가 그 메세지에 액세스 할 수 있게 해주는 것이다.
4. Barriers
*Barriers란? 스레드들이 같은지점에 도착한 것을 확실히 하기 위한 동기화 방법이다. 어떤 스레드도 모든 스레드가 barrier에 도착할 때까지 진행할 수 없다.
4-1) busy-wait & mutex 와 barrier
int counter; //0으로 초기화, 공유변수
int thread_count; //thread개수
pthread_mutex_t barrier_mutex; //counter를 보호하는 lock변수
void *Thread_work(){
pthread_mutex_lock(&barrier_mutex); //lock
counter++;
pthread_mutex_unlock(&barrier_mutex); //unlock
while(counter<thread_count); //busy-wait
} 공유 counter를 두고 mutex 로 보호한다음, 모든 스레드가 도착했다는 것을 counter를 통해 알게되면 스레드들은 그지점을 떠날 수 있게 한다. 하지만 이 방법은 barrier를 시도할 때마다 새로운 counter 변수가 필요하다.
4-2) semaphores와 barrier
int counter; //0으로 초기화
sem_t count_sem; //1로 초기화
sem_t barrier_sem; //0으로 초기화
void* Thread_work(){
sem_wait(&count_sem); // 1.초기상태: counter=0. count_sem=1. barrier_sem=0
if(counter==thread_count -1){
counter=0; //3. n번째 스레드 도착: counter=0
sem_post(&count_sem); //count_sem=1
for(j=0;j<thread_count-1;j++)
sem_post(&barrier_sem); //barrier_sem=9 ->곧 스레드 떠남
}
else{
counter++; // 2.스레드n-1개 도착: counter=9. count_sem=1. barrier_sem=0
sem_post(&count_sem);
sem_wait(&barrier_sem);
}
}
4-3) Pthread barrier
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include <time.h>
#define THREAD_COUNT 4
pthread_barrier_t mybarrier: //barrier 전역변수
void * threadFn(void* id_ptr){
int thread_id=*(int *) id_ptr;
int wait_sec = 1+ rand()%5;
printf("thread %d : Wait for %d seconds /n", thread_id, wait_sec);
sleep(wait_sec);
printf("thread %d : I'm ready...\n",thread_id);
pthread_barrier_wait(&mybarrier);
printf("thread %d : going!\n",thread_id);
return NULL;
}
int main(){
int i;
pthread_t ids[THREAD_COUNT];
int short_ids[THREAD_COUNT];
srand(time(NULL));
pthread_barrier_init(&mybarrier,NULL,THREAD_COUNT+1); //+mainthread
for(i=0;i<THREAD_COUNT;i++){
short_ids[i]=i;
pthread_create(&ids[i],NULL,threadFn,&short_ids[i]); //스레드 생성
}
printf("main() is ready. \n");
pthread_barrier_wait(&mybarrier); //barrier실행
for(i=0;i<THREAD_COUNT;i++)
pthread_join(ids[i],NULL); //스레드 종료
pthread_barrier_destroy(&mybarrier); //barrier 종료
return 0;
}
'Cloud Computing' 카테고리의 다른 글
| 14. 병렬분산 처리 시스템: HADOOP이란? (0) | 2020.12.09 |
|---|---|
| 13. 공유메모리 프로그래밍-OpenMP (0) | 2020.12.09 |
| 10. 병렬프로그래밍: 병렬화가 잘되는 경우 (Embarrassingly Parallel Computations) (0) | 2020.10.22 |
| 9. MPI프로그램 집합통신 (Collective Communication) (0) | 2020.10.21 |
| 8. MPI프로그램 1:1 통신모드 (1:1 Communication Modes) (6) | 2020.10.21 |