*HADOOP이란?
안정적이고 확장가능한 분산 컴퓨팅을 하기 위한 오픈소스 소프트웨어이다. 하둡 소프트웨어 라이브러리는 프레임워크이고, 클러스터 상에 분산 저장되어있는 대용량 데이터셋을 대상으로 분산처리를 가능하게 한다. 단일서버나 수천대의 컴퓨터로 구성된 클러스터 상에도 실행이 가능하고, 클러스터내의 각 컴퓨터에서 로컬 컴퓨팅과 스토리지 기능을 제공한다. 고품질 하드웨어를 사용하는 것이 아니기 때문에 고가용성을 보장하고, 응용레이어에서 자체적으로 오류를 감지하고 해결하도록 라이브러리가 설계되어있다. 하둡은 HDFS에 데이터를 저장하고, YARN으로 리소스를 관리하고 MapReduce로 데이터를 처리한다.

-개발배경: Google에서 모든 데이터를 대상으로 검색엔진을 제공하려는 목적에서 기존의 저장체계와 파일체계로는 대량의 데이터를 대상으로 검색용 인덱스를 만들기 어려웠기 때문에 대용량데이터를 처리할 수 있는 미들웨어를 자체적으로 개발하였다. 2003년의 google file system과 2004년의 MapReduce논문의 내용을 오픈소스로 구현한 것이 바로 하둡이다. Doug Cutting이 개발하였고, 2008년에 아파치의 최상위 프로젝트로 승격되었다.
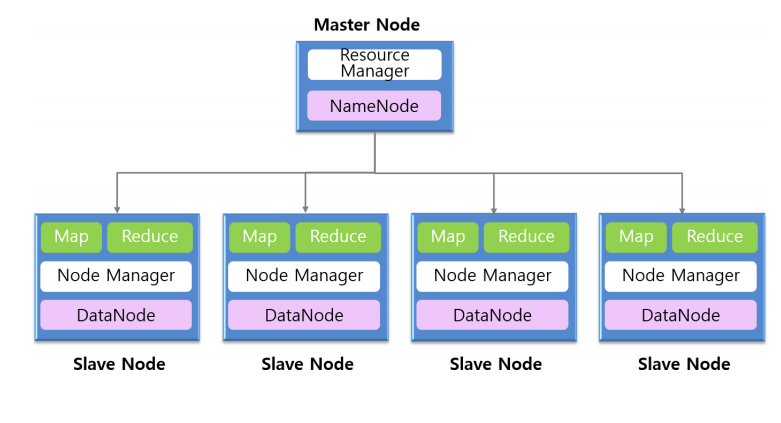
-구조: master-slave구조로 되어있다. master는 task와 data를 slavenode에 할당하고 리소스를 관리한다. master에는 NameNode와 ResourceManager가 있다. slave는 실제 데이터를 저장하고 (meta data 는 master에 존재) 자신이 가지고 있는 데이터를 대상으로 처리한다. slave에는 DataNode, NodeManager, Map, Reduce가 존재한다.
1. HDFS (Haddop Distributed File System)
하둡의 data storage에 해당하는 것으로, 데이터는 block단위로 분할되어 각 slave node에 저장된다. 데이터 관리를 위해 master node에서는 NameNode daemon이 실행되고, 각 slave node에서는 DataNode daemon이 실행된다. 기존의 파일시스템에서는 한대의 컴퓨터 노드 상에서 파일을 관리하기 위한 것이지만, 분산파일시스템은 여러대의 컴퓨터 노드에서 규모가 큰 하나의 파일시스템을 제공한다. 즉, HDFS는 각 slave node에 있는 ext4같은 로컬파일 시스템 상에 만들어지는 오버레이 파일시스템인 것이다. HDFS상에 배치된 파일은 128이나 256MB 크기의 블록으로 분할되어 각 slave node에 저장되지만, 각 블록데이터는 ext4같은 로컬파일시스템의 파일로 취급된다. HDFS는 투과성(클라이언트는 데이터 관리 방식을 모름), 확장성(DataNode 추가가능), 신뢰성(각 블록 3copy 다중기록을 통한 데이터손실방지, NameNode는 HA서버로 구성)의 특징을 가진다. 데이터접근에 대해서는 기록은 1회만하고 후에는 읽기만 허용하며 데이터 변경이 불가능하고 랜덤읽기는 금지된다.
-NameNode: file system namespace를 관리하고 data에 대한 metadata를 저장한다. 파일 열기, 닫기, 이름변경등의 작업을 처리하고, 블록을 DataNode 와 매핑하는 작업을 한다.
-DataNode: 클라리언트가 요구하는 read, write를 file system상에서 처리한다. NameNode의 요구를 처리하고, block의 생성, 삭제, 복제의 작업을 한다.

-Data Replication: file 생성시 replica의 개수를 지정할 수 있고, default는 3개이다. rack awareness algorithm을 사용하여 1rack에 최대 2copy만 저장되게끔 한다. NameNode는 replication과 관련된 모든 것을 결정하고 관리하며, DataNode로부터 주기적으로 heatbeat(datanode가 제기능을 하고있는가)와 blockreport(block정보확인)을 받는다.
2. YARN (Yet Another Resource Negotiator)
yarn에서는 resource management와 job scheduling/monitoring 기능이 분리되어있다.
-Resource Manager: 실행중인 응용 사이에서 리소스를 중재한다.
-Node Manager: 컨테이너가 사용하는 리소스를 모니터링하고, 내용을 Resource Manager에게 보고한다.
-Application Master: Resource Manager와 리소스를 협상하고, Node Manager와 협업하여 일하고 모니터링한다.
3. Map Reduce
Map Reduce는 대규모 데이터 집합을 처리하기 위한 프로그래밍 모델이다. 병렬처리를 위해 job을 여러개의 task로 나누어 실행한다.

-Map: 입력데이터는 HDFS 상의 블록단위로 분할 저장된 파일들이다(split). MapReduce 프레임워크는 각 Map 테스크를 slave node들에게 할당한다. 각 Map 테스크는 동일한 노드에 저장되어있는 블록을 처리한다. 입력데이터(128, 256MB)로부터 key-value쌍을 1개씩 꺼내어 사용자가 정의한 map처리를 수행하고, 처리결과도 key-value형태로 출력한다. 여기서의 처리결과를 intermeidate result라고 부른다.
-Shuffle: Map처리가 끝나면 프레임워크가 intermediate result를 정렬해서 같은 키를 가진 데이터를 같은 노드로 모아준다. 이때 slave node들 사이에 네트워크를 통한 전송이 발생한다. shuffle처리는 MapReduce가 자동으로 수행하므로 사용자가 별도로 처리해줄 것은 없지만 네트워크를 통한 데이터 전송이 발생하는 것을 인지해야한다. 전송데이터양이 크면, Shuffle 처리에 시간이 많이든다.
-Reduce: Shuffle 을 통해 key별로 모아진 데이터에 대해 reduce처리를 한다.
*MapReduce 사용시 주의사항*
-map함수: 처리 대상 데리터 전체를 하나씩 처리한다. 개별 map함수에 데이터를 전달하는 순서는 조정할 수 없다. 따라서 map함수는 처리 대상 데이터간에 의존관계가 없고, 독립적으로 실행가능한 처리나 순서를 고려하지 않아도 되는 처리에 적합하다.
-reduce함수: 키와 연관된 복수의 데이터가 전달된다. 데이터는 키 값으로 정렬되어 있다. 따라서 그룹화된 복수의 데이터를 필요로하는 처리나 순서를 고려해야하는 처리에 적합하다.
'Cloud Computing' 카테고리의 다른 글
| 16. MapReduce Framework (0) | 2020.12.09 |
|---|---|
| 15. MapReduce Program의 구조 (0) | 2020.12.09 |
| 13. 공유메모리 프로그래밍-OpenMP (0) | 2020.12.09 |
| 12. 공유메모리 프로그래밍-Pthreads (2) | 2020.12.08 |
| 10. 병렬프로그래밍: 병렬화가 잘되는 경우 (Embarrassingly Parallel Computations) (0) | 2020.10.22 |