OpenMP란?
공유메모리 환경에서 사용하는 directive-based API로, 프로그래머가 순차 프로그램을 점진적으로 병렬해갈수 있도록 하기위해 설계되었다. 프로그래머가 병렬화 가능한 코드블록을 지정해 놓으면, 그것을 참고로 하여 병렬화는 컴파일러와 런타임 시스템이 결정하고 처리한다.

#pragma opm parallel num_thread(thread_count): 코드 블록을 실행할 쓰레드 개수를 프로그래머가 명시할 때 쓰이는 명령어이다. 하지만 생성하고자 하는 쓰레드 개수를 프로그래머가 프로그램에 명시한다고해도, 시스템은 생성할 수 있는 정도만 생성하고, thread_count만큼 쓰레드를 생성해주지 않을 수도 있다. 요즘 OpenMP는 일반적으로 수천개의 쓰레드까진 생성해준다.
implicit barrier: 쓰레드 하나가 코드블록의 실행을 마쳤다고 해도, 다른 모든 쓰레드들이 그 코드블록의 실행을 마칠때까지 대기한다. 모든 쓰레드가 코드 볼록의 실행을 끝냈을때, slave threads들이 종료되고, master만 남아서 프로그램의 실행을 계속 진행한다.
#예제코드: 적분을 하는 OpenMP 프로그램
#include <stdio.h>
#include <stdlib.h>
#include <omp.h>
void Trap(double a , double b, int n, double *global_result_p);
double f(double x){return 2*x;}
int main(int argc, char *argv[]){
double global_result=0.0;//전역변수
double a,b; //전역변수
int n, thread_count; //전역변수
thread_count=strtol(argv[1],NULL,10);
printf("Enter a,b,n \n");
scanf("%lf %lf %d",&a, &b, &n);
#pragma omp parallel num_threads(thread_count) //스레드가 실행하는곳
Trap(a,b,n,&global_result); //스레드가 실행하는 곳
printf("result=%.14e\n",global_result);
return 0;
}
void Trap(double a, double b, int n, double *global_result_p){
double h,x,my_result,local_a,local_b;
int i,local_n;
int my_rank=omp_get_thread_num(); //스레드 번호
int thread_count=omp_get_num_threads(); //스레드 개수
h=(b-1)/n;
local_n=n/thread_count;
local_a=a+my_rank*local_n*h;
local_b=local_a+local_n*h;
my_result=(f(local_a)+f(local_b))/2.0;
printf("brefore loop %d\n",my_rank);
for(i=1;i<=local_n-1;i++){
x=local_a + i*h;
my_result+=f(x);
}
my_result=my_result*h;
#pragma omp critical
*global_result_p+=my_result; //오직 하나의 스레드만 실행
}
1. Scope of Variables & Reduction
-OpenMP에서의 scope: 변수에 어떤 쓰레드들이 접근할 수 있는가를 나타낸다. team안에 모든 쓰레드가 접근할 수 있다면 shared scope, 쓰레드 1개만이 접근, 사용할 수 있는 변수는 private scope라고 부른다. parallel block을 실행하기 전에 선언된 변수들의 기본 범위는 share이다.
따라서 위의 Trap함수를 바꿔서, 밑의 코드처럼 나타낼 수 있다.
#pragma omp parallel num_threads(thread_count){
double my_result=0.0;
my_result+= Local_trap(a,b,n); //쓰레드들이 병렬로 계산
#pragma omp critical
global_result+=my_result; //더할때는 하나의 쓰레드만
}-Reduction operator: resuction clause에 있는 공유변수가 포함되어있는 명령문을 쓰레드가 실행할 때는 자동적으로 쓰레드가 혼자 사용할 수 있는 private변수가 생성되고, 그 변수에서 reduction operation이 진행된다. 이 private변수에는 identity value로 초기화되어있다. 가능한 operation은 +,*,-,&,|,^,&&,|| 이다.
따라서 위의 Trap함수를 바꿔서, 밑의 코드처럼 나타낼 수 있다.
#pragma omp parallel num_threads(thread_count) reduction(+: global_result)
global_result+=Local_trap(a,b,n);
2. Parallel for Directive
-paralle for directive: 바로 밑에는 for문이 존재하고, 그 for문을 실행하기 위해 여러 쓰레드가 생성되며, 각 쓰레드는 for문의 iteration을 나누어 실행한다. thread 0 은 모든 쓰레드의 실행이 끝날때까지 기다린 후, parallel for를 실행하던 스레드들이 다 종료될때까지 기다린다.
#적분예제코드
h=(b-a)/n;
approx=(f(a)+f(b))/2.0;
#pragma omp parallel for num_threads(thread_count) reduction(+:approx)
for(i=1;i<n-1;i++) //i는 private
approx+=f(a+i*h); //shared
approx=h*approx;하지만 위의 코드는 for문의 iteration이 순서대로 실행되는 것은 아니기때문에 iteration사이의 dependencies를 체크해주지는 않는다. 따라서 loop dependency가 문제되는 변수들을 private scope로 지정해주어야한다.
#파이계산코드
double sum=0.0;
#pragma omp parallelfor num_threads(thread_count) reduction(+:sum) private(factor)
for(k=0;k<n;k++){
if(k%2==0)
factor=1.0;
else
factor=-1.0;
sum+=factor/(2*k+1);
}factor변수는 쓰레드마다 별도로 가질 수 있도록 private으로 지정해주고, iteration마다 계산하여 loop dependency를 제거한다. 만약 프로그래머가 모든 변수들의 scope를 명시하고싶으면 default(none)을 이용하면된다.
#pragma omp parallel for num_threads(thread_count) default(none) resudtion(+:sum) private(k) shared(n)
#Odd-Even Sort코드
#pragma omp parallel num_threads(thread_count) default(none) shared(a.n) private(i,tmp,phase)
for(phase=0;pase<n;phase++){
if(phase%2==0)
#pragma omp for
for(i=1;i<n;i+=2){
if(a[i-1]>a[i]){
tmp=a[i-1];
a[i-1]=a[i];
a[i]=tmp;
}
}
else
#pragma omp for
for(i=1;i<n-1;i+=2){
if(a[i]>a[i+1]){
tmp=a[i+1];
a[i+1]=a[i];
a[i]=tmp;
}
}
}
parallel block을 실행하기 위해 thread_count개수만큼 쓰레드를 생성해놓고, pragma omp for을 실행할때는 이미 생성되어 있는 쓰레드들을 사용해서 for문의 iteration을 실행시킨다.
3. Scheduling Loops
OpenMP 시스템은 환경변수인 OMP_SCHEDULE을 사용해서 loop스케줄을 정한다. OMP_SCHEDULE환경변수로 static, dynamic, guided 스케줄을 모두 선택할 수 있다.
-static: loop가 실행되기전에 itreation들이 쓰레드에 배정된다. static뒤에 써져있는 숫자를 기준으로 chunck의 개수가 할당된다.

-dynamic : loop가 실행되는 과정에 iteration 들을 쓰레드에 배정한다. 인접한 iteration 들을 모아 chuncksize 개수 크기의 chunck로 나누어 놓는다. 각 쓰레드는 chunck를 하나씩 실행하고, 실행이 끝나면 런타임시스템에게 next chunck를 다이나믹하게 요청한다. chuncksize가 생략된 경우에는 1로 간주한다.
-guided: loop가 실행되는 과정에 iteration 들을 쓰레드에 배정한다. dynamic방법과 비슷하지만, 새로받게되는 chunck의크기는 이전chunck보다 점점 작아진다. chunck사이즈를 명시하지 않으면 크기가 1이 될때까지 줄어든다. chunck를 명시하면 새 chunck의 크기는 그 크기까지만 줄어들지만 마지막 chunck의 크기는 chuncksize보다 작을수도 있다.
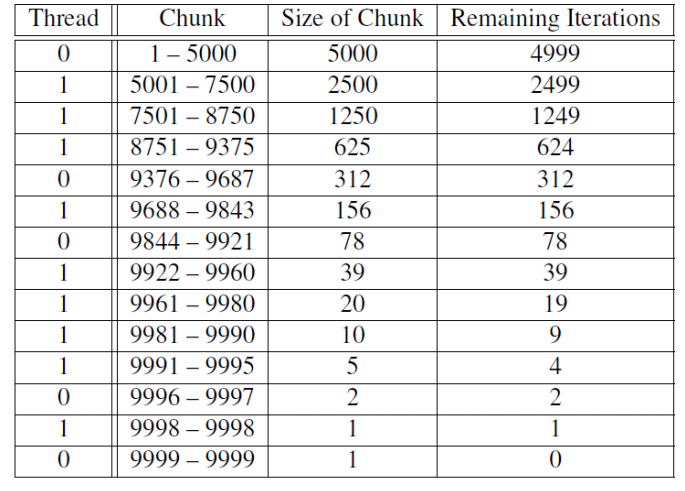
-auto: 컴파일러나 런타임 시스템이 스케줄을 결정한다.
-runtime: 런타임이 스케쥴을 결정한다.
4. lock & atomic
-lock: lock을 사용하여 critical section을 보호할 수 있다. 밑의 코드는 #pragma omp critical 과 같은 역할을 한다.
omp set_lock(&lock);
//critical section
omp unset_lock(&lock);-atomic directive: 보호할 문장이 1개인 경우에 사용할 수 있다.

'Cloud Computing' 카테고리의 다른 글
| 15. MapReduce Program의 구조 (0) | 2020.12.09 |
|---|---|
| 14. 병렬분산 처리 시스템: HADOOP이란? (0) | 2020.12.09 |
| 12. 공유메모리 프로그래밍-Pthreads (2) | 2020.12.08 |
| 10. 병렬프로그래밍: 병렬화가 잘되는 경우 (Embarrassingly Parallel Computations) (0) | 2020.10.22 |
| 9. MPI프로그램 집합통신 (Collective Communication) (0) | 2020.10.21 |