1. MapReduce 프로그램의 구조
public class ExampleClass{
//inner class로, 부모클래스의 인스턴스가 없어도 인스턴스 생성이 가능하도록 static으로 정의
public static vlass MyMapper extends Mapper<K1,V1,K2,V2>{
K2 k2= new K2();
V2 v2=new V2();
public void map (K1 key, V1 value, Context context){
//body
context.write(k2,v2);
}
}
public static class MyReducer extends Reducer<K2,V2,K3,V3>{
K3 k3=new K3();
V3 v3=new V3();
public void reduce(K2 key, Iterable<V2> values, Context context){
//body
context.write(k3,v3);
}
}
public static void main(String[] args)throws Exception{
Configuration conf=new Configuration(); //실행을 위해 job을 framwork에 설명해주는 인터페이스
Job job=Job.getInstance(conf,"job name"); //conf를 가지고 job instance생성
//job instance를 사용하여 각종 초기화 작업수행
//map, reduce클래스 지정
//입력파일의 위치지정
//출력파일이 저장될 위치지정
//입력, 출력 포맷 지정
//맵의 출력 key,value 타입지정
//최종 출력의 key, value 타입지정(다른경우에만)
//job 실행
}
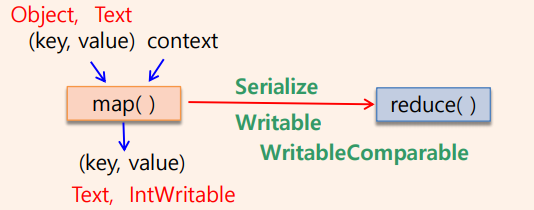
}1) MyMapper 클래스: Mapper 클래스를 상속
Mapper 클래스에 map()메소드가 있으며, 입력(key,value)를 받아 출력(key,value)를 수행한다. K1,V1은 입력이고, K2,V2는 출력이다. Mapper클래스에는 setup(), map(), cleanup(),run()에 대한 메소드가 있다. map()메소드는 하나의 입력쌍에 대해 항상 하나의 출력쌍을 생성하는 것은 아니다.
2)MyReducer 클래스: Reducer 클래스를 상속
Reducer 클래스에 reduce()메소드가 있으며, K2, V2는 입력이고, K3,V3는 출력이다. Reducer클래스에는 setup(), reduce(), cleanup(), run()에 대한 메소드가 있다. map()의 출력 key, value와 reduce()의 입력 key,value의 데이터형은 항상 일치해야한다. reduce()메소드는 항상 하나의 입력쌍에 대해 하나의 출력쌍을 생성하는 것은 아니다.
2. 예제코드: WordCount 프로그램
1) package, import 부분
package wordcount;
import java.io.IOExceptio;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration; //job과 framwork사이 인터페이스
import org.apache.hadoop.fs.Path; //입출력 파일의 path지정
import org.apache.hadoop.io.IntWritable; //MapReduce가 사용하는 데이터타입
import org.apache.hadoop.io.Text; //MapReduce가 사용하는 데이터타입
import org.apache.hadoop.mapreduce.Job; //job클래스
import org.apache.hadoop.mapreduce.Mapper; //mapper클래스
import org.apache.hadoop.mapreduce.Reducer; //Reduce클래스
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; //입력데이터 형식,위치
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; //출력데이터 형식,위치
2) TekenizerMapper 클래스
public class WordCount{
public static class TokenizerMapper extends Mapper<object, Text, Text,IntWritable>{
private final static IntWritable one=new IntWritable(1);//통신이 가능한 정수
private Text word=new Text();//통신이 가능한 string
public void map(Object key, Text value, Context context) throws IOException , InterruptedException{
StringTokenizer itr=new StringTokenizer(value.toString()); //text to string
while(itr.hasMoreToekens()){
word.set(itr.nectToken()); //word에 string을 text로 변환하여저장
context.write(word,one); //map()의 출력 (key,value)쌍은 통신가능타입
}
}
}
*하둡 제공 기본데이터타입
| 타입 | 설명 |
| Text | String에 해당하고, toString()을 사용하여 String형식으로 바꿀 수 있다. |
| IntWritable | int에 해당하고, get()을 호출하여 int로 바꿀 수 있다. |
| LongWritable | long에 해당하고, get()을 호출하여 long으로 바꿀 수 있다. |
| FloatWritable | float에 해당하고, get()을 호출하여 float으로 바꿀 수 있다. |
| BooleanWritable | boolean에 해당하고, get()을 호출하여 boolean으로 바꿀 수 있다. |
| ArrayWritable | 동일한 형의 여러값을 배열처럼 저장한다. |
| NullWritable | null에 해당한다. |
다시 Writable한 형태로 바꾸고 싶다면 set(변수이름)을 호출한다.
3) IntSumReducer 클래스
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result=new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException{
int sum=0;
for(IntWritable val:values){
sum+=val.get(); //int형으로 변환하여 계산
}
result.set(sum); //result에 sum을 IntWritable로 변환하여 저장
context.write(key,result); //출력파일에 저장
}
}
map()함수의 출력 타입과 같은 형으로 입력을 받아야한다.
4) main()에서의 job세팅
public static void main(String[] args)throws Exception{
Configuration conf=new Configuration(); //job을 framework에 설명해주는 인터페이스
Job job=Job.getInstance9conf,"word count"); //comf를 가지고 job instance생성
job.setJarByClass(WordCount.class); //slavenode에 jar파일을 보내 실행시킬때 찾을수있게
job.setMapperClass(TokenizerMapper.class); //mapper클래스 지정
job.setCombinerClass(IntSumReducer.class); //combiner클래스지정(맵이 실행되는 노드에서)
job.setReducerClass(IntSumReducer.class); //reducer클래스지정
job.setOutputKeyClass(Text.class); //output key타입지정
job.setOutputValueClass(IntWritable.class); //output value타입지정
FileInputFormat.addInputPath(job,new Path(args[0])); //입력파일이 있는 폴더지정
FileOutputFormat.setOutputPath(job, new Path(args[1])); //출력파일을 저장할 폴더지정
System.exit(job.waitForCompletion(true)?0:1); //job실행 (성공적이면 0)
}-Combiner의 역할: map함수가 출력한 key, value쌍들을 대상으로 slave node내에서 실행된다. 그 후에, shuffle& sort가 진행된다.
'Cloud Computing' 카테고리의 다른 글
| 16. MapReduce Framework (0) | 2020.12.09 |
|---|---|
| 14. 병렬분산 처리 시스템: HADOOP이란? (0) | 2020.12.09 |
| 13. 공유메모리 프로그래밍-OpenMP (0) | 2020.12.09 |
| 12. 공유메모리 프로그래밍-Pthreads (2) | 2020.12.08 |
| 10. 병렬프로그래밍: 병렬화가 잘되는 경우 (Embarrassingly Parallel Computations) (0) | 2020.10.22 |