자연어가 가지는 중의성이란?
사람은 주변정보를 사용하여 숨겨진 의미를 파악하지만, 기계에게 주어지는 것은 텍스트이기 때문에 자연어 처리분야에서 중의성을 해결하는 것은 굉장히 중요한 부분이다. 형태는 같으나 뜻은 서로 다른 동형어, 한 형태의 단어가 여러 의미를 지닌 다의어의 경우에는 꼭 중의성을 해소(Word-Sense Disambiguation)하여 의미를 명확히 해야한다. 또한 의미가 같은 단어들은 동의어 집합으로 묶고, 상위어와 하위어의 단어 구조를 계층화하여 자연어처리에 유용하게 쓸 수 있다.
1. 원 핫 인코딩 (One-Hot Encoding)

단 하나의 1과 나머지의 0으로 이루어진 벡터를 이용한 표현방법을 말한다. 벡터의 차원은 전체 어휘의 개수가 되며, 보통 3만에서 10만까지의 범위를 가진다. 단어는 불연속적이기 때문에 이산확률변수로 나타내고, 원핫 벡터는 이산확률 분포로 뽑아낸 샘플이라고 할 수 있다. 하지만 벡터의 차원이 너무 커져 희소벡터(벡터의 상당부분이 0인 벡터)의 특징을 가지게 되었고, 이는 벡터간 연산을 할 때 결과값이 0이 되는 문제를 초래한다.
2. 워드넷 (WordNet)
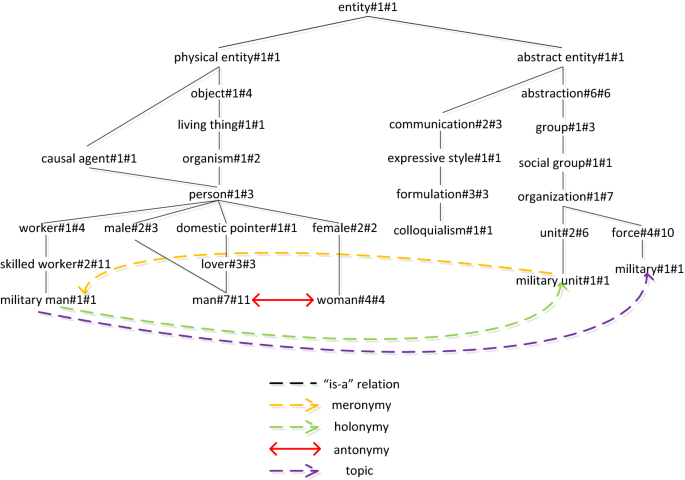
단어의 계층구조를 파악하여 데이터베이스로 구축한 것을 시소러스(어휘분류사전)이라고 부른다. 이 시소러스를 대표하는 것에는 워드넷이 있다. 워드넷은 단위에 대한 상위어와 하위어의 정보를 구축하여 유향비순환그래프(Directed Acyclic Graph)의 모양을 띈다. 한국어를 위한 워드넷에는 KorLex와 KWN이 있다. 시소러스 기반의 정보를 활용하면 코퍼스가 없어도 단어간 유사도를 구할 수 있지만, 사전을 구축하는 것은 많은 비용과 시간이 소모되므로 한계가 있다.
레스크 알고리즘은 시소러스 기반 중의성 해소 방법이다. 문장 내에 같이 등장하는 단어는 공통 토픽을 공유한다는 가정하에 문장내의 단어들끼리 사전에서 의미별 설명사이의 유사도를 구한다. 그 중 가장 유사도가 높은 의미를 선택하는데, 사전에만 크게 의존하게 되기 때문에 문장에 많은 정보가 없을 경우 좋은 결과값을 얻기 힘들다.
3. 특징벡터 (Feature Vector)
효과적으로 정보를 추출하기 위해선 그 대상의 특징을 잘 표현해야 한다. 데이터의 각 샘플들마다 수치를 가지게 되는데, 이 수치들을 모아 벡터로 표현한 것을 특징벡터라고 한다.
1) 특징 추출하는 법 : TF-IDF
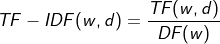
TF-IDF는 출현빈도를 사용하여 어떤 단어 w가 문서 d 내에서 얼마나 중요한지 나타내는 수치이다. TF는 단어의 문서내에 출현한 횟수를 의미하고, DF는 해당단어가 출현한 문서의 수이다. 즉, 우리가 얻는 수치는 다른 문서들에는 잘 나타나지 않지만, 현재 문서에서는 많이 등장하는 단어일수록 높아진다.
2) 특징벡터 만들기
TF 행렬을 이용하여 특징벡터를 만들 수도 있지만, 문서에 대한 단어별 출현횟수를 특징벡터로 삼으면, 매우 단순화되고 많은 정보가 유실되어 자연어처리에는 적합하지 않다. 따라서 컨텍스트 윈도우를 활용하여 함께 출현한 단어들의 정보를 뽑아낸다. 윈도우를 움직이며 그 안에 있는 단어들의 출현빈도를 세어 행렬로 나타내는 것이다. 하지만 이 방법도 희소벡터들이 많기 때문에 차원축소를 통해 해결해주어야 한다.

3) 벡터유사도 구하는법
단어들은 불연속적인 형태이지만 내부적으로 의미를 가지기 때문에, 단어 사이에는 유사성을 가진다. 특징벡터를 활용하면 단어 사이의 유사도를 측정할 수 있다.
-L1거리: 맨해튼 거리, 두 벡터의 각 차원별 값의 차이를 절대값으로 모두 합한 값
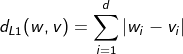
-L2거리: 유클리디안 거리, 차원별 값 차이의 제곱의 합에 루트를 취한 값
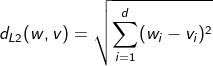
-Infinity Norm: 차원별 값의 차이 중 가장 큰 값

-코사인 유사도: 자연어 처리에서 가장 널리 쓰이는 유사도 기법, 1에 가까울수록 방향이 일치하고 0에 가까울수록 직교이며, -1에 가까울수록 반대방향을 뜻한다. 하지만 희소벡터일 경우 윗변이 벡터 곱으로 표현되기 때문에 정확한 값을 구하기 어렵다.
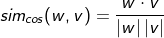
-자카드 유사도: 두 집한 간의 유사도, 두 집한 간의 교집합 크기를 합집합 크기로 나눈 값, 다만 수치 자체에 대해 구할경우에는 min, max 연산을 활용한다.
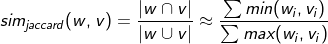
4. 선택 선호도(Selectional Preference)
선택 선호도는 단어와 단어 사이의 관계가 좀 더 특별한 경우를 나타낸다. 예를들어 "사용하다"라는 술어가 있을 때, "음식"보다는 "물건"의 클래스에 있는 단어들이 등장할 확률이 높을 것이다. 필립래스닉은 선택선호도강도를 쿨백-라이블러 발산(KLD)를 사용하여 정의하였다.

선택 선호도 강도는 w가 주어졌을때의 object class C의 분포 P(C|w)와 해당 클래스들의 사전분포 P(C)와의 KLD로 정의되어져 있다. 즉, 술어가 표제어로 특정클래스를 얼마나 선택적으로 선호하는지에 대한 수치라는 것이다.
워드넷을 통해 단어의 상위어를 클래스로 삼는다면 선택 선호도를 잘 활용할 수 있을 것이다. 필립래스닉은 술어와 클래스 사이의 확률분포를 정의하는 출현빈도의 계산수식을 제안했는데, 술어w와 함께 출현한 단어 h의 빈도를 세고, h가 속하는 클래스의 집합의 크기로 나눈것이다.
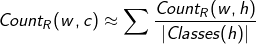
이에 반해, 카트린 어크는 시소러스에 의지하지 않고 데이터를 기반으로 선택선호도를 구하는 방법을 제시하였다.
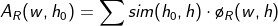
※본 게시물은 「김기현의 자연어처리 딥러닝캠프-파이토치편」을 참고하여 작성되었습니다.
'NLP' 카테고리의 다른 글
| 7. 시퀀셜 모델링 (0) | 2021.07.23 |
|---|---|
| 6. 단어 임베딩 (0) | 2021.07.21 |
| 4. 전처리 (0) | 2021.07.19 |
| 3. 파이토치 기초문법 (0) | 2021.07.13 |
| 2. 자연어처리를 위한 기초수학 (0) | 2021.07.13 |