전처리란?
머신러닝 또는 딥러닝 학습을 위해 데이터를 사용할 때, 모델이 사용가능할 수 있는 형태로 변환하고 품질을 올리는 과정을 전처리과정이라고 한다. 자연어처리에서 자주 등장하는 코퍼스(corpus)는 한국말로 말뭉치라고도 하며, 여러 단어들로 이루어진 문장을 뜻한다. 코퍼스가 많고 오류가 없을수록 자연어처리 모델의 정확도가 높아진다. 자연어처리에서 전처리과정은 코퍼스수집-> 정제 -> 문장단위분절 -> 분절 -> 병렬코퍼스 정렬 -> 서브워드 분절 의 과정으로 이루어진다. 이제부터 하나씩 살펴보려고 한다.
1. 코퍼스 수집
공개된 데이터를 사용하거나 크롤링을 통하여 코퍼스를 수집할 수 있다. 한가지 언어로 구성된 단일언어 코퍼스는 인터넷에 널려있기 때문에 수집하기 쉽지만, 목적에 맞게 적절한 코퍼스를 수집하는 것이 중요하다. 한편, 여러개의 언어로 구성된 다중언어 코퍼스는 보통 기계번역을 위해 쓰인다. 이때 자막을 사용할 경우에는, 문화에 따른 번역의 차이가 있기 때문에 데이터를 사용하기 전에 많은 부분을 고려하여야 한다.
| 문체 | 도메인 | 수집처 | 정제난이도 |
| 대화체 | 일반 | 채팅로그 | 상 |
| 대화체 | 일반 | 블로그 | 상 |
| 대화체 | 일반 | 클리앙 | 중 |
| 대화체 | 일반 | 드라마, 영화자막 | 하 |
| 문어체 | 시사 | 뉴스기사 | 하 |
| 문어체 | 과학, 고양, 역사 | 위키디피아 | 중 |
| 문어체 | 과학, 요양, 역사, 서브컬쳐 | 나무위키 | 중 |
| 문어체 | 일반, 시사 | PGR21 | 중 |
도메인별 단일언어 코퍼스 수집사례
2. 정제
텍스트를 사용하기에 앞서, 모델이 사용할 수 있게끔 필요한 형태를 얻어내는 과정을 말한다.
1) 전각문자 제거: 한국어 문서의 숫자, 영어, 기호 등이 전각문자일때는 일반적으로 사용되는 반각문자로 바꾸어 주어야 한다. 전각문자는 하나의 글자가 정사각형을 이루는 문자를 의미하고, 반각문자는 전각문자의 가로 폭을 반으로 줄인 문자를 의미한다.
2) 대소문자 통일: 일부 영어 코퍼스에서는 약자를 쓰면서 하나의 의미를 지니는 단어를 대문자 또는 소문자로 통일하여 표현을의 희소성을 줄이는 것이 좋다. 하지만 단어 임베딩을 통한 표현이 가능해지면서 대소문자 구분에 대한 문제는 줄어들었다.
3) 정규표현식: 크롤링을해서 얻어낸 코퍼스는 기호에 의해 노이즈가 섞일 때가 있고, 개인정보가 포함된 문서의 경우 이들을 제거하고 학습에 이용하여야 한다.
| 표현식 | 의미 |
| ^x | 문자열의 시작을 표현하고, x문자로 시작된다는 뜻 |
| x$ | 문자열의 종료를 표현하고, x문자로 종료된다는 뜻 |
| .x | . 은 어떤 문자도 올 수 있으며, 문자열이 x로 끝난다는 뜻 |
| x+ | x문자가 한번 이상 반복된다는 뜻 |
| x? | x문자가 존재할수도 존재하지 않을 수도 있다는 뜻 |
| x* | x문자가 0번또는 그 이상 반복된다는 뜻 |
| x|y | x또는 y문자가 존재한다는 뜻 |
| (x) | 그룹을 표현하며 x를 그룹으로 처리한다는 뜻 |
| (x)(y) | 그룹들의 집합을 표현하며 x,y는 각 그룹의 데이터로 관리된다는 뜻 |
| x{n} | x문자가 n번 반복된다는 뜻 |
| x{n,} | x문자가 n번이상 반복된다는 뜻 |
| x{n,m} | x문자가 n번이상 m번이하 반복된다는 뜻 |
| [x-z] | x~z 사이 범위에 있는 글자를 나타내는 뜻 |
| [xy] | 문자선택을 표현하며 x와 y중 하나를 나타내는 뜻 |
정규표현식 주요 문법
3. 문장단위분절
정제를 거친 코퍼스의 대부분의 경우 문장들이 연속해서 등장하기 때문에, 한 라인당 한 문장만 존재하도록 문장단위로 분절을 해주어야 한다. 단순히 마침표만을 이용하여 분절한다면, 문장단위 이외의 곳에서 분절이 될 수 있으므로 자연어 처리 툴킷인 NLTK를 사용하는 것이 좋다.

4. 분절
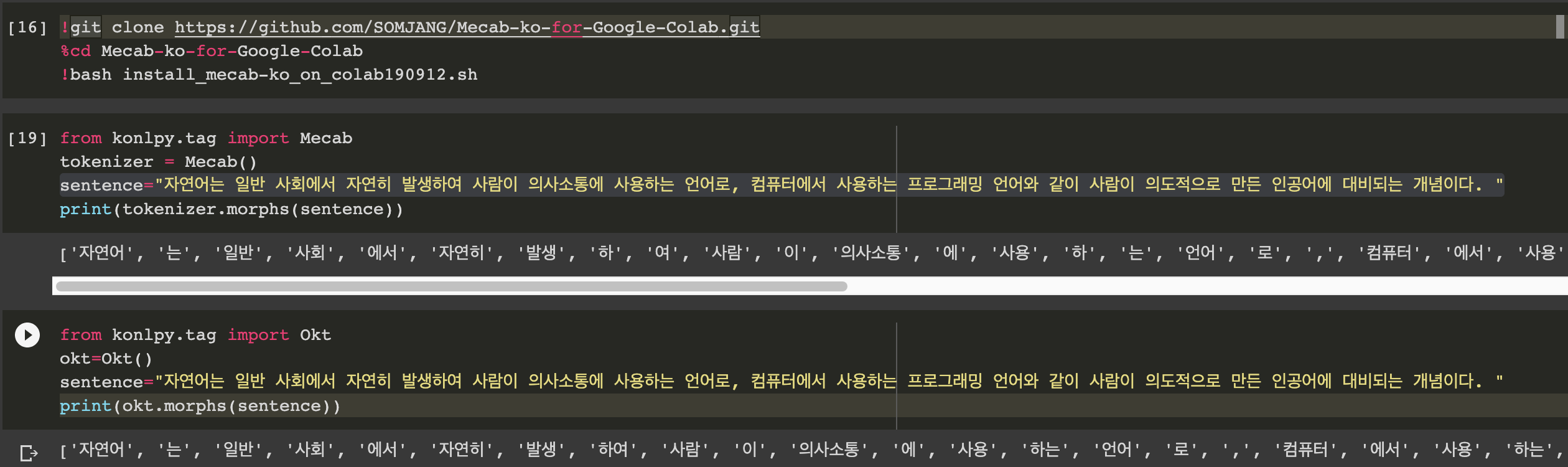
한국어의 경우, Mecab이나 KoNLPy를 이용하여 분절이 가능하다. 먼저 Mecab은 한국어 분절에 가장 많이 사용되는 프로그램으로, 속도는 빠르나 설치가 까다로운 편이다. KoNLPY는 여러 한국어 형태소 분석기들을 모아놓은 랩핑 라이브러리를 제공하는데, 설치와 사용이 쉬우나 속도가 느리다.
5. 토치텍스트
토치텍스트는 자연어 처리문제와 텍스트에 관한 머신러닝이나 딥러닝을 수행하는데 데이터를 읽고 전처리하는 과정을 모아놓은 라이브러리이다. 토치텍스트는 파일로드, 토큰화, 단어집합, 정수인코딩, 단어벡터, 배치화 의 기능을 제공한다.
from torchtext import data
from konlpy.tag import Mecab
from torchtext.legacy import data
tokenizer = Mecab()
class DataLoader(object):
def __init__(self, train_fn, valid_fn, batch_size=64, device=-1, max_vocab=999999, min_freq=1, use_eos=False, shuffle=True):
super(DataLoader, self).__init__()
#필드정의: 앞으로 어떤 전처리를 할 것인지 정의
LABEL=data.Field(sequential=True, #시퀀스 데이터 여부
use_vocab=True, #단어 집합을 만들것인지 여부
unk_token=None)
TEXT=data.Field(sequential=True,
use_vocab=True,
tokenize=tokenizer.morphs, #어떤 토큰화함수를 사용할 것인지 지정
lower=True, #영어 데이터를 모두 소문자화
batch_first=True, #미니배치차원을 맨앞으로하여 데이터를 불러올 것인지
fix_length=20) #최대허용길이 (이것에 맞춰 패딩진행)
#데이터셋 만들기: 토큰화를 수행하면서 데이터를 불러오기
train, valid=data.TabularDataset.splits(path='',
train=train_fn,
valid=valid_fn,
format='tsv',
fileds=[('label', LABEL), ('text',TEXT)])
#단어집합 만들기: 각 단어에 고유한 정수를 맵핑하는 정수 인코딩작업을 위해 단어집합 생성
TEXT.build_vocab(train, max_size=max_vocab,min_freq=min_freq)
LABEL.build_vocab(train)
※본 게시물은 「김기현의 자연어처리 딥러닝캠프-파이토치편」을 참고하여 작성되었습니다.
'NLP' 카테고리의 다른 글
| 6. 단어 임베딩 (0) | 2021.07.21 |
|---|---|
| 5. 자연어의 중의성을 해결하는 법 (0) | 2021.07.21 |
| 3. 파이토치 기초문법 (0) | 2021.07.13 |
| 2. 자연어처리를 위한 기초수학 (0) | 2021.07.13 |
| 1. 자연어 처리란? (0) | 2021.07.13 |