1. 자연어 처리, NLP
Natural Language Processing, 줄여서 NLP는 인공지능의 한 분야로, 컴퓨터가 사람의 언어를 이해하고 처리하는 기술을 말한다. 요약, 기계 번역, 감정분석, QA 등 많은곳에서 응용된다. 인간의 언어는 단어간의 순서가 고려되는 시퀀셜 데이터기 때문에 딥러닝 분야에서 상대적으로 나중에 발전되어 왔지만, end to end 모델로 대체되면서 빠르게 발전되어 왔다.
*시퀀셜데이터(sequential data): 순차 데이터라고도 하며, 데이터의 집합 내에서 객체들이 순서를 가진 데이터이다. 순서가 변경되면 데이터가 변경된다.
*end-to-end: 어떤 문제를 해결함에 있어서 여러가지 과정들을 하나의 신경망을 통해서 재배치 하는과정. 하나의 파이프라인을 하나의 신경망으로 해결할 수 있다.

전통적인 심볼릭 기반 접근 방법은 사람의 언어인 불연속적인 이산심벌을 그대로 취급하여, 사람이 인지하기 쉽고 디버깅이 용이하다는 장점이 있지만 연산속도가 느리고 모호성과 유의성에 취약하다는 단점이 있었다. 하지만 딥러닝을 기반으로 접근하면서, 문장은 토크나이징과 단어임베딩을 거쳐 연속적인 벡터로 나타날 수 있게 되었고, 모호성과 유의성을 해결하였다.
2. 자연어 처리가 어려운 이유
- 모호성: 단어가 여러 뜻을 가지는 경우 또는, 문장 내에 정보가 부족한 경우에는 모호성이 발생한다.
Ex1) 조각 배에 앉아서 배를 먹다보니 배가 불러 집으로 향했다.
Ex2) 나는 당근요리를 한적이 없다. (내가 아니라 다른사람이 한건지, 당근요리대신 다른요리를 한건지, 아니면 둘다인지)
-불연속적인 데이터: 딥러닝에는 연속적인 값이 쓰여 불연속적인 자연어 데이터를 연속적인 값으로 바꾸어 주어야 한다. 현재는 단어 임베딩이 해결해주고 있지만, 노이즈처리와 정제과정에서 값이 잘못되면 문장의 의미가 크게 변할 수 있기 때문에 여전히 어려운 문제이다.
-교착어: 영어와 중국어는 어순에 따라 단어의 문법적 기능이 정해지지만, 교착어인 한국어는 어간에 접사가 붙어 단어를 이루고 문법적 기능이 정해지기 때문에 형태소를 분석함에 있어서 매우 큰 어려움이 있다.
-의문문: 영어, 중국어와 달리 한국어는 평서문에 물음표만 붙여도 질문을 나타내기 때문에 다른언어에 비해 판단하기 어렵다. 음성인식을 그대로 받아쓴 텍스트를 분류하게 될 때, 많은 경우 물음표가 포함되지 않기 때문이다.
3. 자연어 처리의 역사
-2010년: RNN을 화용한 언어 모델을 시도하여 기존 n-gram 기반 언어모델의 한계를 극복하려했으나, 높은 연산량으로 인해 해결하지는 못했다.
-2013년: 구글의 토마스 미코로프가 Word2Vec을 발표한다. 2-layer linear MLP를 활용한 단순한 신경망을 사용하였고, 비슷한 의미의 단어일수록 비슷한 벡터값을 갖게 한다.
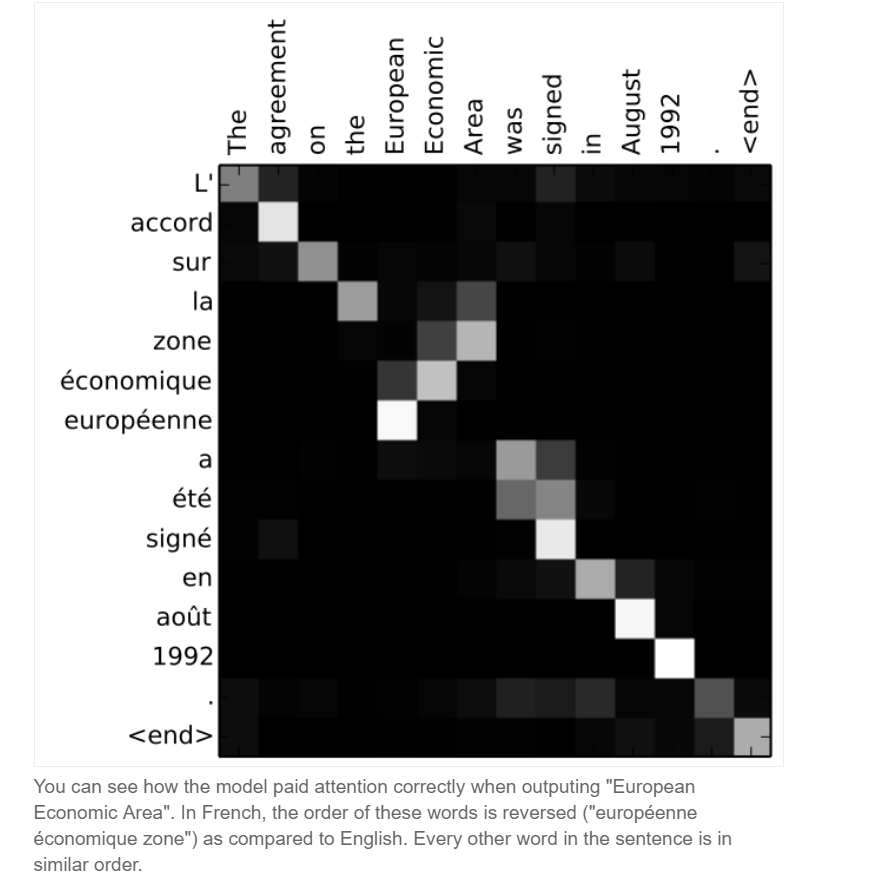
-2014년: Seq2Seq와 attention기법이 개발되어 기계번역에 탁월한 성과를 보였다. 기계번역은 가장먼저 end-to-end 방식을 활용하여 상용화에 성공했다.
-그 이후: 메모리를 활용하여 NTM(Neural Turing Machine)과 DNC(Different Neural Computer)가 제시되었고, 강화학습을 활용하여 SeqGAN과 같이 GAN을 구현하는 방법이 제시되기도 하였다.
※본 게시물은 「김기현의 자연어처리 딥러닝캠프-파이토치편」을 참고하여 작성되었습니다.
'NLP' 카테고리의 다른 글
| 6. 단어 임베딩 (0) | 2021.07.21 |
|---|---|
| 5. 자연어의 중의성을 해결하는 법 (0) | 2021.07.21 |
| 4. 전처리 (0) | 2021.07.19 |
| 3. 파이토치 기초문법 (0) | 2021.07.13 |
| 2. 자연어처리를 위한 기초수학 (0) | 2021.07.13 |