1. 차원축소
높은 차원에서 자연어를 벡터로 추출하는 과정에서 희소성 문제가 많이 나타난다. 따라서 낮은 차원으로 정보를 효율적으로 표현하는 차원축소가 필요하다. 대표적인 차원축소의 방법으로는 주성분 분석(Principal Component Analysis)이 있다. 고차원에서의 데이터를 임의의 평면에 투사했을때 투사한 점들간의 사이가 최대한 멀어야 하며, 투사될때 원래 벡터와 투산된 점의 거리가 최소가 되어야 한다는 조건을 지키며 낮은차원으로 압축하게 된다. 하지만 투사하는 순간 거리가 생기므로, 정보의 손실이 일어날 수 밖에 없기때문에 매니폴드 가설을 통해 좀더 효과적으로 접근해야한다.

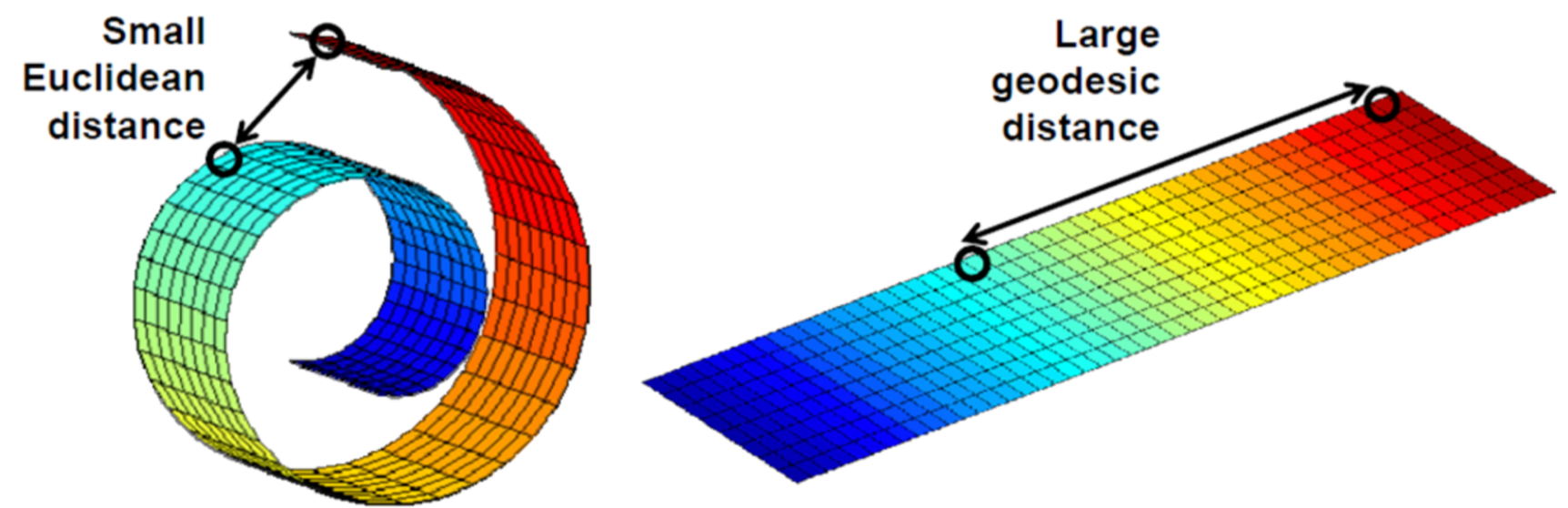
매니폴드 가설이란, 높은차원에 존재하는 데이터들의 경우에는 실제로 해당데이터들을 아우르는 낮은 차원의 매니폴드가 존재한다는 것을 말한다. 3차원의 공간에 분포한 데이터를 구부러진 2차원으로 표현한다면, 선형 투사하여 생긴 손실을 줄일 수 있을 것이다. 또한 고차원에서 가까울지라도 저차원의 매니폴드에서는 거리가 오히려 멀어질 수 있으며, 저차원의 공간상에서 가까운 점은 비슷한 특징을 갖는다는 것을 알 수 있다. 대부분의 딥러닝이 차원축소를 수행하는 과정은 고차원상에서 매니폴드를 찾는 과정과도 같다고 할 수 있다.
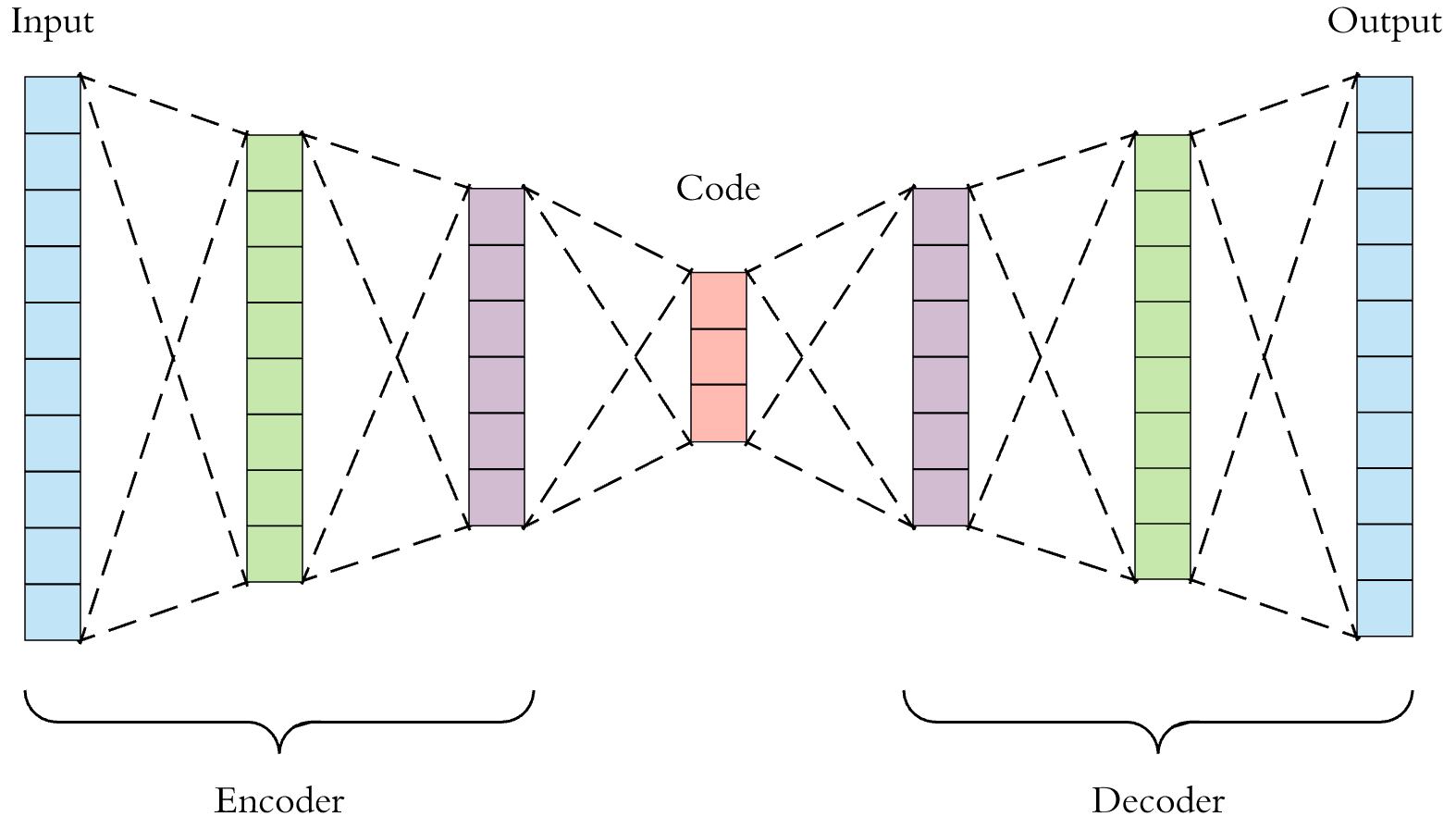
또한 자연어 처리에서는 매니폴드와 더불어 오토인코더라는 딥러닝 모델이 쓰인다. 고차원의 샘플벡터를 받아 매니폴드를 찾은다음, 저차원으로 축소하는 인코더를 거쳐 hidden vector로 표현한다. 디코더는 저차원의 벡터를 받아 다시 샘플이 존재하던 고차원으로 복원한다. 이 과정애서 오토인코더는 병목의 차원이 매우 낮기 때문에 복원에 필요하지 않은 정보는 모두 버려야 한다. 여기서 모델을 훈련할때 복원데이터와 실제데이터의 차이를 최소화하도록 손실함수를 구성한다.
2. Word2Vec

2013년 토마스 미콜라프는 Word2Vec이라는 방법을 제시하여 자연어 분야에 큰 파장을 일으킨다. Word2Vec은 단어를 임베딩하는 방법으로 CBOW와 Skip-gram을 사용한다. 두가지 방법 모두 윈도우의 크기가 주어지면 특정 단어를 기준으로 윈도우 내의 단어들을 사용하여 학습한다. CBOW(Continuous Bag Of Words)는 주변에 나타나는 단어들을 원핫 벡터로 입력받아 해당단어를 예측하게 하고, Skip-gram은 반대로 대상 단어를 원핫 벡터로 입력받아 주변에 나타나는 단어를 예측한다. Skip-gram이 성능이 더 뛰어난 편이고, 널리 쓰인다. Skip-gram은 MLE를 통해 argmax내의 수식을 최대로 하는 파라미터 Θ를 찾는다. Wt가 주어졌을때, 앞 뒤 n개의 단어(Wt-nv~Wt+n)을 찾도록 훈련되는 것이다.


3. GloVe
2014년 스탠포드대학에서 제시한 임베딩 방법으로, Word2Vec만큼 뛰어난 성능을 보여준다. GloVe는 대상 단어에 대해서 코퍼스에 함께 나타난 단어별 출현빈도를 예측하도록 한다. Skip-gram과의 차이점은 분류문제가 아닌, 출현빈도를 근사하는 회귀문제가 되었기 때문에 평균제곱오차 MSE를 이용한다는 것이다. 코퍼스 전체를 훑으며 학습하는 과정을 반복하는 Skip-gram과는 달리, 단어별 동시 출현빈도를 조사하여 근사하기 때문에 학습이 빠르다는 장점이 있고, 사전확률이 낮은 단어에 대해서 학습기회가 적은 Skip-gram의 단점을 보완했다는 평가를 받는다.

이것 또한 마찬가지로 원핫 벡터 x를 입력으로 받아 한개의 은닉층 W를 거쳐 출력층을 통해 툴력벡터를 반환한다. 출력벡터는 코퍼스에 출현했던 모든 단어의 동시출현빈도를 나타낸 벡터인 Cx에 근사하게 되는데, 이는 경사하강법을 통해 학습할 수 있다. 하지만 이때 단어 x의 출현빈도나 사전확롤에 따라 MSE손실함수의 값의 크기가 크게 달라질 수 있기 때문에 단어의 빈도에 따라 손실함수에 가중치를 부여하는 방법을 이용한다.
'NLP' 카테고리의 다른 글
| 8. 텍스트 분류 (0) | 2021.07.23 |
|---|---|
| 7. 시퀀셜 모델링 (0) | 2021.07.23 |
| 5. 자연어의 중의성을 해결하는 법 (0) | 2021.07.21 |
| 4. 전처리 (0) | 2021.07.19 |
| 3. 파이토치 기초문법 (0) | 2021.07.13 |